介绍
Kafka是一个分布式的、可分区的、可复制的消息系统。它提供了普通消息系统的功能,但具有自己独特的设计。这个独特的设计是什么样的呢?
首先让我们看几个基本的消息系统术语:
•Kafka将消息以topic为单位进行归纳。
•将向Kafka topic发布消息的程序成为producers.
•将预订topics并消费消息的程序成为consumer.
•Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker.
producers通过网络将消息发送到Kafka集群,集群向消费者提供消息,如下图所示:
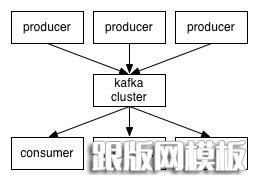
客户端和服务端通过TCP协议通信。Kafka提供了Java客户端,并且对多种语言都提供了支持。
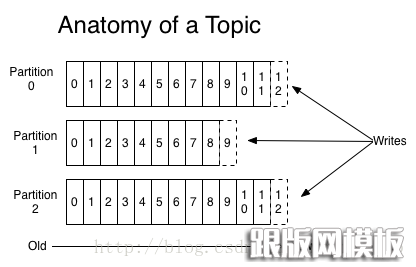
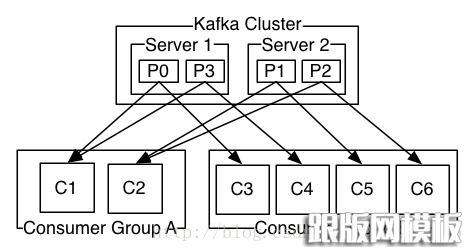
每个分区都由一个服务器作为“leader”,零或若干服务器作为“followers”,leader负责处理消息的读和写,followers则去复制leader.如果leader down了,followers中的一台则会自动成为leader。集群中的每个服务都会同时扮演两个角色:作为它所持有的一部分分区的leader,同时作为其他分区的followers,这样集群就会据有较好的负载均衡。
Consumers
接下来一步一步搭建Kafka运行环境。
> tar -xzf kafka_2.9.2-0.8.1.1.tgz > cd kafka_2.9.2-0.8.1.1Step 2: 启动服务
> bin/zookeeper-server-start.sh config/zookeeper.properties &[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)...现在启动Kafka:
> bin/kafka-server-start.sh config/server.properties[2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties)[2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)...Step 3: 创建 topic
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test可以通过list命令查看创建的topic:
> bin/kafka-topics.sh --list --zookeeper localhost:2181test
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test This is a messageThis is another message
ctrl+c可以退出发送。Step 5: 启动consumerKafka also has a command line consumer that will dump out messages to standard output.
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginningThis is a messageThis is another message
你在一个终端中运行consumer命令行,另一个终端中运行producer命令行,就可以在一个终端输入消息,另一个终端读取消息。
> cp config/server.properties config/server-2.properties在拷贝出的新文件中添加以下参数:
config/server-1.properties: broker.id=1 port=9093 log.dir=/tmp/kafka-logs-1 config/server-2.properties: broker.id=2 port=9094 log.dir=/tmp/kafka-logs-2
> bin/kafka-server-start.sh config/server-1.properties &...> bin/kafka-server-start.sh config/server-2.properties &...创建一个拥有3个副本的topic:
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
> bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topicTopic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
下面解释一下这些输出。第一行是对所有分区的一个描述,然后每个分区都会对应一行,因为我们只有一个分区所以下面就只加了一行。
向topic发送消息:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic...my test message 1my test message 2^C消费这些消息:
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic...my test message 1my test message 2^C
> ps | grep server-1.properties7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.6/Home/bin/java...> kill -9 7564
> bin/kafka-topics.sh --describe --zookeeper localhost:218192 --topic my-replicated-topicTopic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
> bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic my-replicated-topic...my test message 1my test message 2^C
看来Kafka的容错机制还是不错的。
<dependency>
<groupId> org.apache.kafka</groupId >
<artifactId> kafka_2.10</artifactId >
<version> 0.8.0</ version>
</dependency>

配置程序
首先是一个充当配置文件作用的接口,配置了Kafka的各种连接参数:
package com.sohu.kafkademon;
public interface KafkaProperties
{
final static String zkConnect = "10.22.10.139:2181";
final static String groupId = "group1";
final static String topic = "topic1";
final static String kafkaServerURL = "10.22.10.139";
final static int kafkaServerPort = 9092;
final static int kafkaProducerBufferSize = 64 * 1024;
final static int connectionTimeOut = 20000;
final static int reconnectInterval = 10000;
final static String topic2 = "topic2";
final static String topic3 = "topic3";
final static String clientId = "SimpleConsumerDemoClient";
}
producer
package com.sohu.kafkademon;
import java.util.Properties;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
/**
* @author leicui bourne_cui@163.com
*/
public class KafkaProducer extends Thread
{
private final kafka.javaapi.producer.Producer<Integer, String> producer;
private final String topic;
private final Properties props = new Properties();
public KafkaProducer(String topic)
{
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "10.22.10.139:9092");
producer = new kafka.javaapi.producer.Producer<Integer, String>(new ProducerConfig(props));
this.topic = topic;
}
@Override
public void run() {
int messageNo = 1;
while (true)
{
String messageStr = new String("Message_" + messageNo);
System.out.println("Send:" + messageStr);
producer.send(new KeyedMessage<Integer, String>(topic, messageStr));
messageNo++;
try {
sleep(3000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
consumer
package com.sohu.kafkademon;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
/**
* @author leicui bourne_cui@163.com
*/
public class KafkaConsumer extends Thread
{
private final ConsumerConnector consumer;
private final String topic;
public KafkaConsumer(String topic)
{
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
createConsumerConfig());
this.topic = topic;
}
private static ConsumerConfig createConsumerConfig()
{
Properties props = new Properties();
props.put("zookeeper.connect", KafkaProperties.zkConnect);
props.put("group.id", KafkaProperties.groupId);
props.put("zookeeper.session.timeout.ms", "40000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
@Override
public void run() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext()) {
System.out.println("receive:" + new String(it.next().message()));
try {
sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
运行下面这个程序,就可以进行简单的发送接收消息了:简单的发送接收
package com.sohu.kafkademon;
/**
* @author leicui bourne_cui@163.com
*/
public class KafkaConsumerProducerDemo
{
public static void main(String[] args)
{
KafkaProducer producerThread = new KafkaProducer(KafkaProperties.topic);
producerThread.start();
KafkaConsumer consumerThread = new KafkaConsumer(KafkaProperties.topic);
consumerThread.start();
}
}
高级别的consumer
下面是比较负载的发送接收的程序:
package com.sohu.kafkademon;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
/**
* @author leicui bourne_cui@163.com
*/
public class KafkaConsumer extends Thread
{
private final ConsumerConnector consumer;
private final String topic;
public KafkaConsumer(String topic)
{
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
createConsumerConfig());
this.topic = topic;
}
private static ConsumerConfig createConsumerConfig()
{
Properties props = new Properties();
props.put("zookeeper.connect", KafkaProperties.zkConnect);
props.put("group.id", KafkaProperties.groupId);
props.put("zookeeper.session.timeout.ms", "40000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
@Override
public void run() {
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic, new Integer(1));
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream<byte[], byte[]> stream = consumerMap.get(topic).get(0);
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while (it.hasNext()) {
System.out.println("receive:" + new String(it.next().message()));
try {
sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
不要畏惧文件系统!
Kafka大量依赖文件系统去存储和缓存消息。对于硬盘有个传统的观念是硬盘总是很慢,这使很多人怀疑基于文件系统的架构能否提供优异的性能。实际上硬盘的快慢完全取决于使用它的方式。设计良好的硬盘架构可以和内存一样快。
在6块7200转的SATA RAID-5磁盘阵列的线性写速度差不多是600MB/s,但是随即写的速度却是100k/s,差了差不多6000倍。现代的操作系统都对次做了大量的优化,使用了 read-ahead 和 write-behind的技巧,读取的时候成块的预读取数据,写的时候将各种微小琐碎的逻辑写入组织合并成一次较大的物理写入。对此的深入讨论可以查看这里,它们发现线性的访问磁盘,很多时候比随机的内存访问快得多。
为了提高性能,现代操作系统往往使用内存作为磁盘的缓存,现代操作系统乐于把所有空闲内存用作磁盘缓存,虽然这可能在缓存回收和重新分配时牺牲一些性能。所有的磁盘读写操作都会经过这个缓存,这不太可能被绕开除非直接使用I/O。所以虽然每个程序都在自己的线程里只缓存了一份数据,但在操作系统的缓存里还有一份,这等于存了两份数据。
另外再来讨论一下JVM,以下两个事实是众所周知的:
•Java对象占用空间是非常大的,差不多是要存储的数据的两倍甚至更高。
•随着堆中数据量的增加,垃圾回收回变的越来越困难。
基于以上分析,如果把数据缓存在内存里,因为需要存储两份,不得不使用两倍的内存空间,Kafka基于JVM,又不得不将空间再次加倍,再加上要避免GC带来的性能影响,在一个32G内存的机器上,不得不使用到28-30G的内存空间。并且当系统重启的时候,又必须要将数据刷到内存中( 10GB 内存差不多要用10分钟),就算使用冷刷新(不是一次性刷进内存,而是在使用数据的时候没有就刷到内存)也会导致最初的时候新能非常慢。但是使用文件系统,即使系统重启了,也不需要刷新数据。使用文件系统也简化了维护数据一致性的逻辑。
所以与传统的将数据缓存在内存中然后刷到硬盘的设计不同,Kafka直接将数据写到了文件系统的日志中。